
Les LLM de pointe ne parviennent pas à réaliser aucune tâche sur le nouveau benchmark ARC AGI 3
Dans les dernières semaines, nous avons vu la sortie de LLM puissants tels que Qwen 3 MoE, Kimi K2 et Grok 4. Nous continuerons de voir de telles améliorations rapides dans le futur proche, et pour comparer les LLM entre eux, nous avons besoin de benchmarks. Dans cet article, je discute du nouveau benchmark ARC AGI 3 récemment publié et pourquoi les LLM de pointe ont du mal à réaliser toute tâche sur ce benchmark.
Motivation
Nous annonçons aujourd’hui un aperçu d’ARC-AGI-3, le benchmark de raisonnement interactif avec le plus grand écart entre facile pour les humains et difficile pour l’IA.
Nous publions :
* 3 jeux (environnements)
* Un concours d’agents de 10 000 $
* Une API d’agents IAScores initiaux – IA de pointe : 0 %, Humains : 100 % pic.twitter.com/3YY6jV2RdY
— ARC Prize (@arcprize) 18 juillet 2025
ARC AGI 3 a été récemment publié.
Ma motivation pour écrire cet article est de rester au courant des derniers développements en matière de technologie LLM. Ce n’est que dans les dernières semaines que nous avons vu les modèles Kimi K2 (le meilleur modèle open source lors de sa sortie), Qwen 3 235B-A22B (actuellement le meilleur modèle open source), Grok 4, et ainsi de suite. Il se passe tellement de choses dans l’espace LLM, et une façon de se tenir au courant est de suivre les benchmarks.
Je trouve le benchmark ARC AGI particulièrement intéressant, principalement parce que je veux voir si les LLM peuvent atteindre un niveau d’intelligence comparable à celui des humains. Les énigmes ARC AGI sont conçues pour que les humains puissent les résoudre, mais les LLM auront du mal.
Table des matières
- Introduction à ARC AGI
- Jouer au benchmark ARC AGI
- Pourquoi les modèles de pointe n’obtiennent qu’un score de 0 %
- Longueur du contexte
- Ensemble de données d’entraînement
- Performances du benchmark dans le futur
- Chasse aux benchmarks
- Conclusion
Introduction à ARC AGI
ARC AGI est essentiellement un jeu d’énigmes de correspondance de motifs.
- ARC AGI 1 : On vous donne une série de paires entrée-sortie, et vous devez compléter le motif
- ARC AGI 2 : Similaire au premier benchmark, effectuant une correspondance de motifs sur les exemples d’entrée et de sortie
- ARC AGI 3 : Ici, vous jouez à un jeu où vous devez déplacer votre bloc vers la zone cible, mais certaines étapes requises sont comprises entre les deux.
Je trouve cool de tester ces jeux d’énigmes et de les résoudre moi-même. Ensuite, vous pouvez voir les LLM initialement avoir du mal avec les benchmarks, puis augmenter leurs performances avec de meilleurs modèles. OpenAI, par exemple, a obtenu :
- 7,8 % avec o1 mini
- 75 % avec o3-low
- 88 % avec o3-high
Comme vous pouvez le voir également dans l’image ci-dessous :
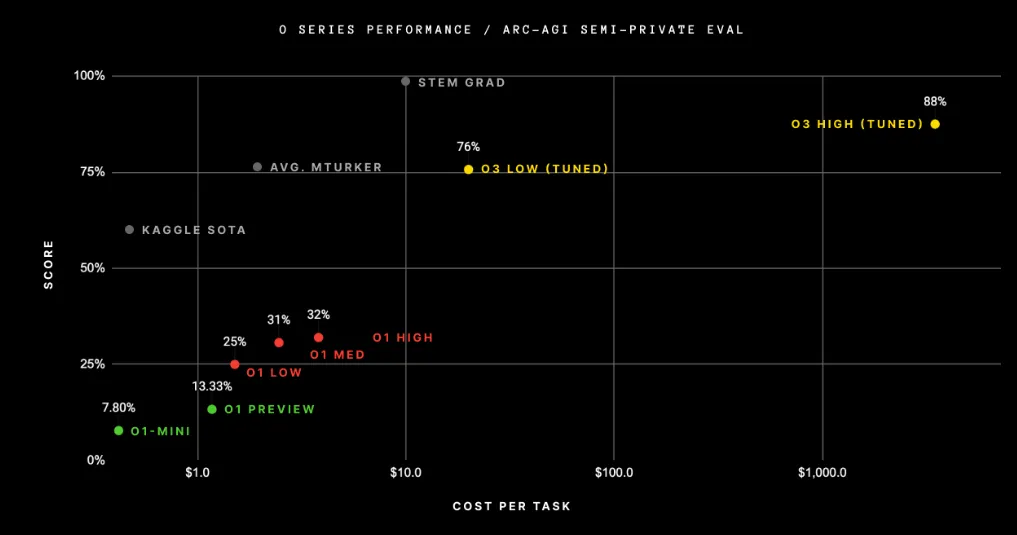
Cette image montre les performances des différents modèles OpenAI sur le benchmark ARC AGI 1. Vous pouvez voir comment les performances augmentent avec des modèles plus avancés. Image de ARC AGI, sous la licence Apache 2.
Jouer au benchmark ARC AGI
Vous pouvez également essayer les benchmarks ARC AGI vous-même ou créer une IA pour effectuer les tâches. Rendez-vous sur le site Web ARC AGI 3 et commencez à jouer.
Tout l’intérêt des jeux est que vous n’avez aucune instruction, et vous devez comprendre les règles vous-même. J’apprécie ce concept, car il représente une tâche où l’intelligence humaine peut encore surpasser les LLM. Il faut comprendre les règles par soi-même.
Pourquoi les modèles de pointe n’obtiennent qu’un score de 0 %
Je trouve que ce benchmark représente une tâche où l’intelligence humaine peut encore surpasser les LLM. Je trouve ce concept amusant et j’aime imaginer des LLM qui s’améliorent sans cesse.
Chasse aux benchmarks
Il est important de consacrer une section à la chasse aux benchmarks. La chasse aux benchmarks est le concept selon lequel les fournisseurs de LLM cherchent à obtenir des scores optimaux sur les benchmarks, plutôt que de simplement créer les meilleurs ou les LLM les plus intelligents. C’est un problème car la corrélation entre les performances du benchmark et l’intelligence du LLM n’est pas de 100 %.
Dans le monde de l’apprentissage par renforcement, la chasse aux récompenses serait appelée piratage de l’environnement. Il s’agit d’une situation où l’agent trouve un moyen de pirater l’environnement dans lequel il se trouve pour obtenir une récompense, sans effectuer correctement une tâche.
La raison pour laquelle les fournisseurs de LLM font cela est que chaque fois qu’un nouveau modèle est publié, les gens regardent généralement deux choses :
- Performances du benchmark
- Vibe
Les performances du benchmark sont généralement mesurées sur des benchmarks connus, tels que SWE-bench et ARC AGI. Tester le « vibe » est également un moyen pour le public de mesurer les LLM (je ne dis pas que c’est une bonne façon de tester le modèle, je dis simplement que cela arrive dans la pratique). Le problème est que, dans ce cas, il est assez simple d’impressionner les gens avec le « vibe » d’un modèle, car le test du « vibe » tente d’explorer un très petit pourcentage de l’espace d’action du LLM. Vous ne lui posez peut-être que des questions disponibles sur le Web, ou vous lui demandez de programmer une application que le modèle a déjà vue 1000 fois dans ses données d’entraînement.
Par conséquent, ce que vous devriez faire est d’avoir votre propre benchmark, par exemple un ensemble de données qui n’a pas été divulgué sur Internet. Ensuite, vous pouvez comparer les LLM pour voir lequel fonctionne le mieux pour votre cas d’utilisation et donner la priorité à l’utilisation de ce LLM.
Conclusion
Dans cet article, j’ai discuté des benchmarks LLM et de leur importance pour comparer les LLM. J’ai présenté le nouveau benchmark ARC AGI 3, qui a été publié. J’espère que cela se fera de manière continue pour améliorer les LLM en termes d’intelligence et pas seulement améliorer les performances en termes de benchmark.




{kind=link}